AI:人工智能在捉迷藏游戏中表现出令人惊讶的行为
研究人员已经发布消息,让他们的人工智能野心发挥出一种强大的捉迷藏游戏,带来了令人生畏的结果。代理商的环境有墙壁和可移动的箱子,以挑战一些人,其中一些是寻找者,其他人,寻求者。一路上发生了很多事,带来了惊喜。
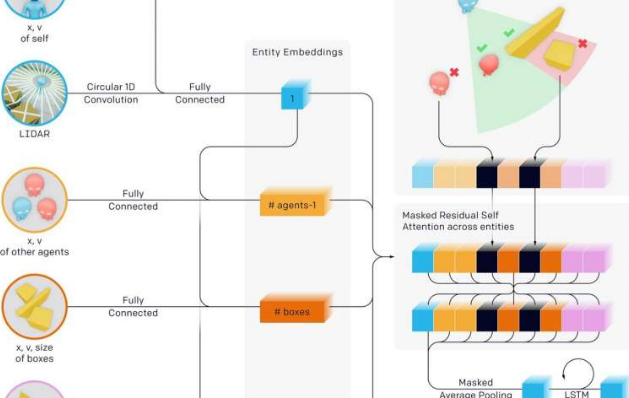
作者陈述了所学的内容,他们写道:“我们观察到代理人在玩一个简单的捉迷藏游戏时逐渐发现更复杂的工具使用,”代理人建立了“一系列六种截然不同的策略和反策略,其中一些我们不知道我们的环境得到了支持。“
在本周早些时候发布的一篇新论文中,该团队公布了结果。他们的论文“来自Multi-Agent Autocurricula的Emergent Tool Use”有七位作者,其中六位已列出OpenAI表示,另一位是Google Brain。
作者评论了他们正在采取什么样的挑战。“创建能够解决各种复杂的人类相关任务的智能人工智能因素一直是人工智能领域的长期挑战。”
该团队表示,“我们发现代理人创建了一个自我监督的自动课程,引发了多轮不同的紧急策略,其中许多需要复杂的工具使用和协调。”
通过捉迷藏,(1)寻求者学会追逐学会逃跑的躲藏者和躲藏者(2)Hiders学会了基本的工具用途和墙壁来建造堡垒。(3)寻求者学会了使用坡道跳入躲避者的庇护所(4)躲藏者学会将匝道移到远离他们建造堡垒的地方,并将它们锁定到位(5)寻求者知道他们可以从锁定的坡道跳到箱子并将箱子冲到躲藏者的避难所。(6)在建造堡垒之前,躲藏者学会了锁住未使用过的箱子。
这六种策略是作为代理人在捉迷藏中相互训练而出现的 - 每种新策略都为代理人进入下一阶段创造了以前不存在的压力,没有任何直接激励代理人与对象交互或探索。这些策略是多智能体竞争和捉迷藏动态引发的“自动课程”的结果。
博客中的作者说,他们了解到“通常情况下,代理商会找到一种方法来以无意的方式利用您构建的环境或物理引擎。”
发生的事情是“自我监督的紧急复杂性”。而这“进一步表明,多智能体共同适应可能有一天会产生极其复杂和智能的行为。” 作者在他们的论文中同样指出,“在物理基础和开放式环境中诱导自动调节可能最终使代理人能够获得无限数量的与人类相关的技能。”
道格拉斯天堂,新科学家,真正引起了读者对他描述发生的事情的兴趣:
“起初,躲避者只是逃跑了。但是,他们很快就发现,找到寻求者的最快方法是找到环境中的物体以隐藏自己的视线,将它们当作一种工具使用。例如,他们学会了这些箱子可以用来挡住门口并建造简单的藏身处。求职者了解到他们可以移动一个坡道并用它来爬过墙壁。然后机器人发现,作为一个团队玩家 - 彼此传递物体或合作隐藏 - 是获胜的最快方式。“
这是一个雄心勃勃的项目。在审查他们的工作时,麻省理工学院技术评论指出,人工智能在近5亿次捉迷藏游戏后学会了使用工具。通过玩捉迷藏,数以亿计的轮次,两个对立的AI代理团队制定了复杂的隐藏和寻求策略。
Karen Hao提供了一个有趣的标记,表明经纪人在多少轮之后学到了什么:“...围绕着2500万游戏标记,游戏变得更加复杂。躲藏者学会了移动并锁定环境中的盒子和路障以建立围绕着自己进行斗争,以便寻求者永远不会看到他们。“
更多的数百万轮:寻求者发现了一种反策略,因为他们学会了在躲避者堡垒旁边移动一个坡道并用它爬过墙壁。更多回合后,躲藏者学会了在建造堡垒之前将斜坡锁定到位。
然而,更多的战略出现在3.8亿的比赛中。出现了另外两种策略。寻求者们制定了一项战略,通过使用一个锁定的坡道爬上一个未锁定的箱子,然后在箱子顶部“冲浪”到堡垒和墙壁上来打入闯入者的堡垒。在最后阶段,护匠再次学会在建造堡垒之前将所有坡道和箱子锁定到位。
郝引用了该报的作者之一鲍文贝克。“我们没有告诉躲猫猫或寻求者在一个盒子附近奔跑或与之互动...但是通过多智能体竞赛,他们为对方创造了新的任务,以便其他团队不得不适应。”
考虑一下。贝克说,他们并没有告诉刽子手,他们没有告诉寻求者,在箱子附近跑,也不与他们互动。
TechCrunch的 Devin Coldewey 想到了这一点。“该研究旨在并成功地研究了机器学习代理人学习复杂的,与现实世界相关的技术的可能性,而不会受到研究人员建议的干扰。”
Coldewey把所有这些工作都带回了家。“正如该论文的作者解释的那样,这就是我们出现的方式。”
我们和人类一样。科德威从他们的论文中引用了一段话。
“地球上的大量复杂性和多样性由于生物之间的共同进化和竞争而演变,由自然选择引导。当一个新的成功策略或突变出现时,它改变了邻近代理人需要解决的隐含任务分布并创造了一个新的适应的压力。这些进化的军备竞赛创造了隐含的自动竞争,竞争者不断为彼此创造新的任务。“